
Modélisez vos forêts en 3D et réalisez un inventaire forestier
Le drone équipé d’un lidar (scanner laser) permet de numériser rapidement une forêt.
Les bénéfices du drone en forêt
- Réaliser un inventaire forestier (comptage, hauteur, diamètre, essence …)
- Calculer la quantité de carbone sequestrée (carbone et CO2)
- Aider à la gestion forestière via une carte des hauteurs de la canopée
- Identifier les arbres dépérissant via l’imagerie multispectrale
- Restaurer des milieux humides via une analyse des réseaux hydrographiques
- Planifier le déplacement des engins forestiers via un modèle topographique
- Prévenir les incendies via la production d’une carte de combustibilité
- Estimer les dégâts à la suite d’une tempête ou d’un incendie
Utilisez le LiDAR pour analyser vos forêts
Le capteur LiDAR est un scanner en mouvement et fonctionne donc sur le principe du laser. Les rayons émis par le laser permettent de traverser la canopée d’une forêt et d’avoir de l’information au niveau du sol et de la structure des arbres. Une fois numérisée, le modèle de forêt est traité de manière algorithmique afin de déterminer les informations clés à la production d’un inventaire forestier.
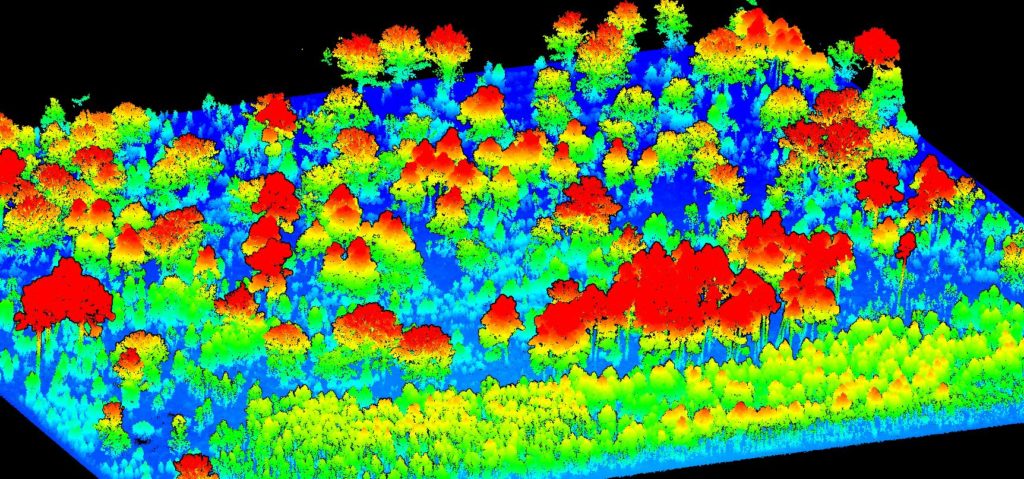
Une cartographie en haute définition pour des analyses avancées
Profitez d’un déploiement rapide et d’un gain de temps grâce à la flexibilité du drone et à l’automatisation des missions.
Acquisition de données (LiDAR, photo, multispectral, satellite)
Nous utilisons les capteurs adaptés à votre besoin. Nous pouvons par exemple couplé le LiDAR à la photogrammétrie pour vous restituer à la fois un MNT et une orthophotographie en haute résolution.
En savoir plus
Production de cartes (hauteur de canopée, densité de peuplement …)
Le relevé LiDAR nous permet de produire les différentes cartes utiles à la gestion des forêts. Cette cartographie permet notamment de mieux comprendre la répartition par hauteur, par densité, par volume ou essence.
En savoir plus
Scanforest propose une solution nouvelle et une méthodologie unique adaptée aux besoins des gestionnaires de forêt
Les drones DJI de la gamme Matrice et le lidar LiAir V de GreenValley garantissent une acquisition de données précises tout en offrant un déploiement rapide.
Un matériel adapté à la collecte de données précises
Le drone DJI Matrice 210 équipé d’un lidar est en mesure d’effectuer des missions complexes de collectes de données destinées à l’arpentage, la foresterie, l’hydrologie, l’étude environnementale, l’exploitation minière, l’aménagement du territoire ou encore l’archéologie.
Avec ses 3 échos, le Lidar LiAir V scanne 100 000 points par seconde jusqu’à 260 mètres de distance.

Un LiDAR avec une tête Livox Mid-40 ultra performante
Le capteur Mid-40 utilise un modèle de balayage non répétitif avancé pour fournir des détails très précis dans le champ de vision.
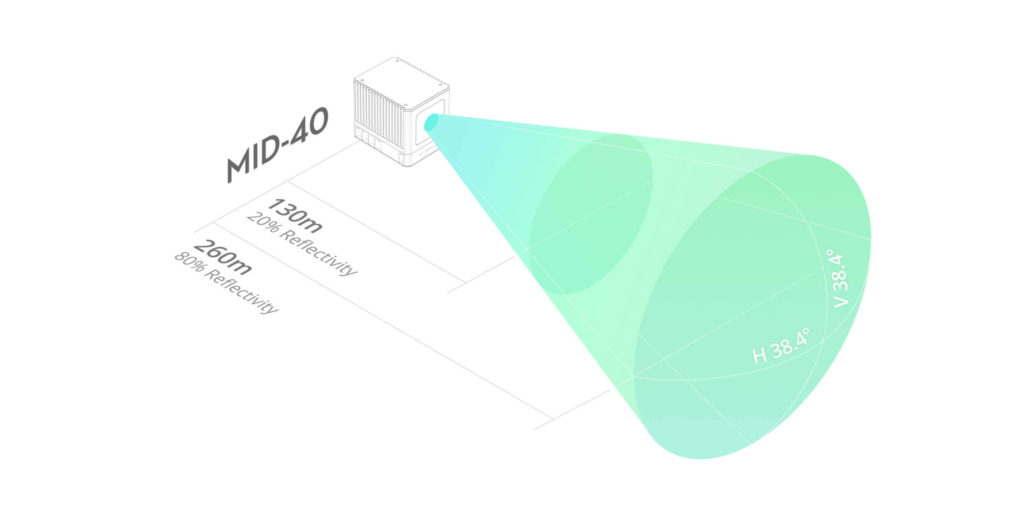
Un taux d’échantillonnage de 100.000 points par seconde
Un champ de vision circulaire de 38,4°
Détection des objets dans un rayon de 260 mètres
Des outils informatiques adaptés au traitement des données forestières
Nos logiciels propriétaires, spécialisés dans le traitement de données photos, lidar et multispectral, nous permettent d’effectuer des traitements sur-mesure adaptés à vos parcelles (feuillus et résineux)
Acquisition de données LiDAR, photos, multispectrales …
Nous utilisons les capteurs adaptés à votre besoin. Nous pouvons par exemple couplé le LiDAR à la photo RVB pour vous restituer à la fois un MNT et une orthophotographie en haute résolution. La photo ci-contre met en ainsi en évidence un arbre dépérissant. Le capteur multispectral permet également de calculer un indice de la vitalité de l’arbre.


Production de modèles complexes (3D, terrain, hauteur …)
Un relevé LiDAR par drone permet de produire rapidement un modèle 3D de la forêt, un modèle numérique de terrain (MNT), un modèle de hauteur de canopée. Sur demande nous pouvons vous fournir les études de votre choix : calcul de la hauteur des arbres, inventaire forestier, production d’un modèle hydrographique …
L’intelligence artificielle permet d’aider à la gestion des forêts
Les techniques de machine learning appliquées au secteur de la foresterie apportent une information intelligible et précise sur la forêt
Classification et machine learning
Entraînez des modèles de machine learning sur vos données afin de leur apprendre à reconnaître automatiquement des formes. Ces modèles peuvent ainsi résoudre des tâches telles que la segmentation des arbres, le calcul du diamètre à 1,30 m, la surveillance du dépérissement des arbres et la détection de maladies …
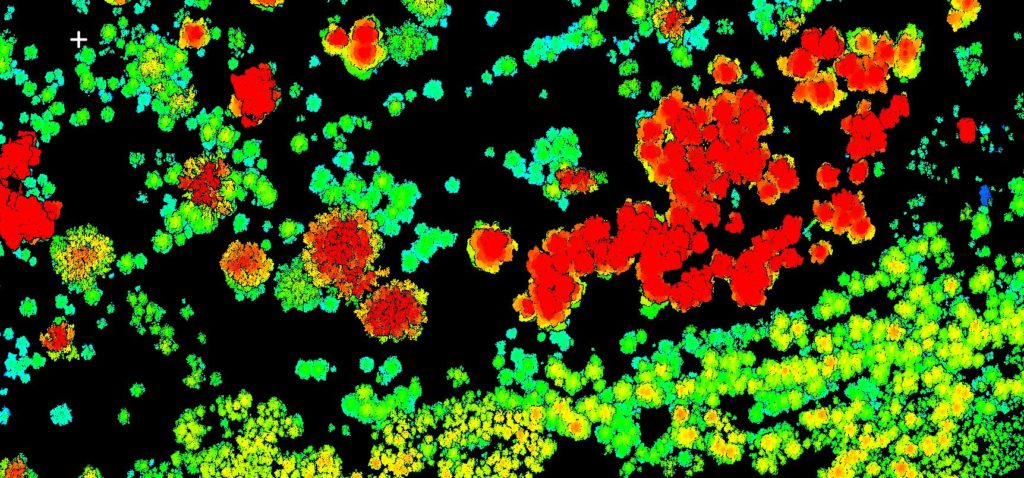
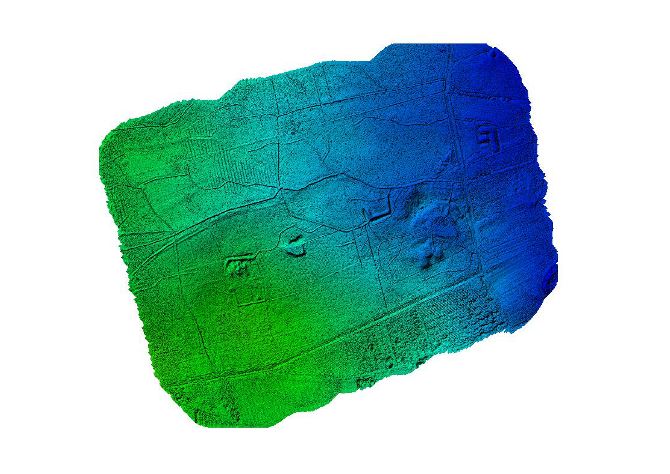
Topographie complète du terrain
Vous souhaitez savoir quels secrets cachent votre forêt ? Nous générons un modèle numérique de terrain permettant d’avoir une topographie claire et précise du sol. Ce modèle peut être notamment utilisé pour déterminer les routes de débardage ou encore pour comprendre l’écoulement de l’eau.
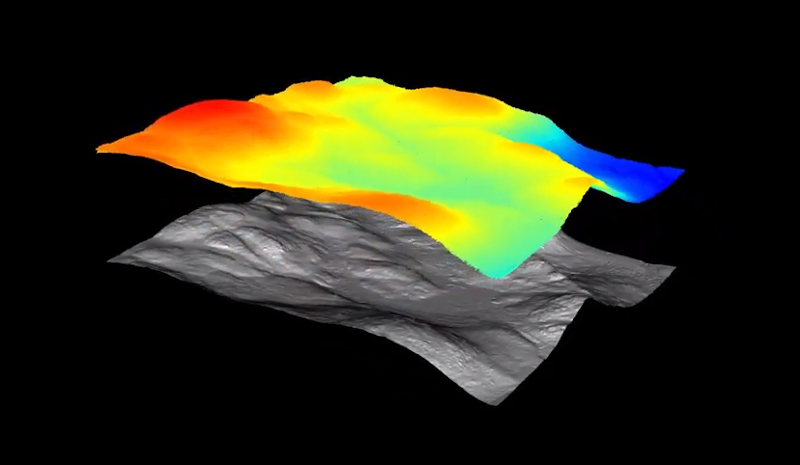
Soustraction du modèle numérique de terrain
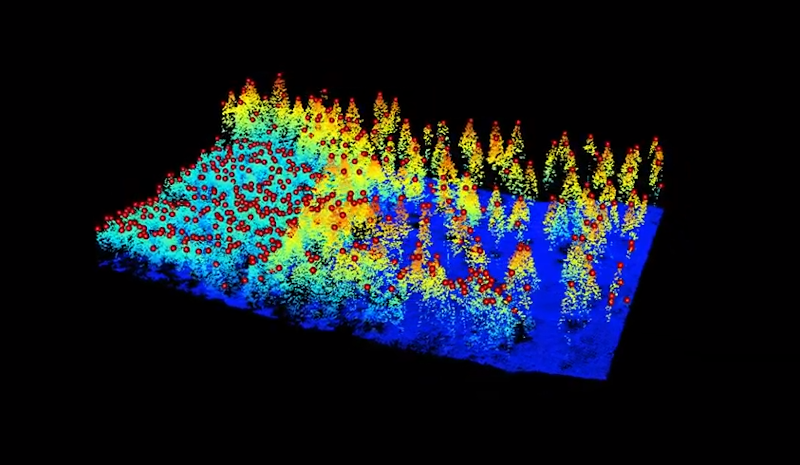
Détection des cimes

Extraction des arbres individuels

Segmentation des arbres

Modèle numérique de peuplement
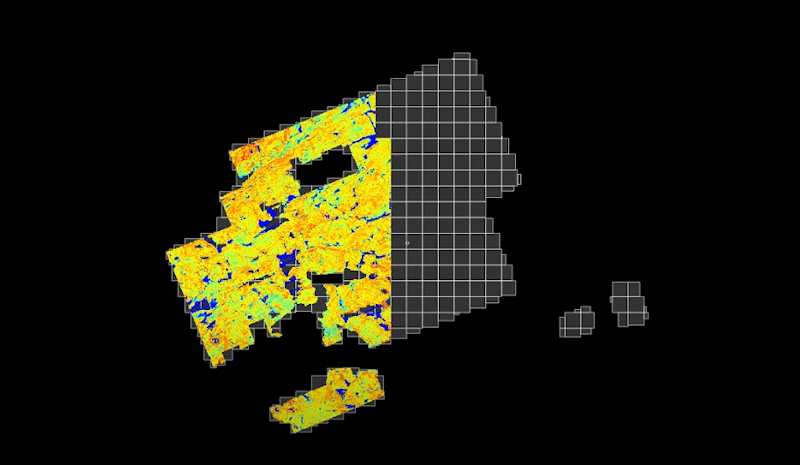
Traitement par tuile pour les grandes surfaces
Contactez-nous dès maintenant
Un projet à réaliser ? Nous vous répondons dans la journée !
Une question ? Contactez nos experts
Quelle est la différence entre la photogrammétrie et la lasergrammétrie ?
La photogrammétrie se base sur des photographies prises à différents angles afin de reconstruire un modèle 3D tandis que la lasergrammétrie se base sur le principe du laser afin de déterminer la position des points dans l’espace et de modéliser ainsi tout un nuage 3D.
Qu’est qu’une carte de pentes ?
Une carte de pentes est un fichier matriciel (raster) qui fournit des valeurs réelles numériques représentant des pentes. Ce produit est généré à partir du modèle numérique de terrain. La carte des pentes est utile comme soutien aux opérations forestières ou à la construction de routes et de sentiers (ex : tracer des voies de vidange praticables).
Dans quels cas utiliser un drone équipé d’un lidar ?
Le lidar aéroporté sera très efficace pour modéliser les niveaux d’un terrain recouvert de végétation. Cette technique est très employée en foresterie, en hydrologie, en aménagement du territoire ou en encore pour faire des recherches archéologiques.
Qu’est-ce qu’un MHC ?
Le modèle de hauteur de canopée (MHC) est un fichier matriciel (raster) qui fournit des valeurs numériques représentant la hauteur de la canopée forestière ou d’autres éléments surélevés (p. ex., bâtiments). Ce produit correspond à la différence entre le modèle numérique de surface et le modèle numérique de terrain. Le MHC permet les mesures de hauteur, de densité et de structure des peuplements. Il peut permettre d’établir des relations statistiques pour cartographier les volumes, les surfaces terrières, etc.